Explorer l'IA explicable chez Evovest
Tout le monde est maintenant conscient que les modèles d'apprentissage automatique, également appelés modèles d'IA, ont de nombreuses utilisations dans différents domaines. Cependant, ces modèles sont comme des boîtes noires : plus le modèle est complexe, plus il est difficile à interpréter. Cela crée un manque de transparence lorsque l'on essaie de comprendre pourquoi la machine prend telle ou telle décision. Dans le secteur financier en particulier, il est nécessaire de comprendre le raisonnement qui sous-tend chaque décision.
Avec le développement constant de nouvelles méthodes, de plus en plus de techniques sont examinées et utilisées dans l'IA explicable (XAI). Nous, chez Evovest, avons également exploré quelques-unes de ces techniques, dans l'espoir qu'elles nous aident à comprendre les décisions prises par nos modèles.
Les principales techniques que nous avons découvertes sont la valeur de Shapley et le LIME.
La valeur de Shapley a été introduite en 1951 par Shapley, Lloyd S. [1], puis implémentée dans l'apprentissage automatique par Scott M Lundberg et Su-In Lee [2] en 2017. Nous vous suggérons les lectures en référence, notre bref commentaire en page 4 ou une recherche rapide sur Google pour vous familiariser avec le concept.
En bref, la valeur de Shapley est la contribution marginale moyenne attendue d'une caractéristique vers la prédiction finale après que toutes les combinaisons possibles aient été considérées.
LIME (Local interprétable model-agnostic explanations) est une technique permettant d'approximer tout modèle d'apprentissage automatique de type boîte noire avec un modèle local interprétable pour expliquer chaque prédiction individuelle. Elle a été développée par Marco Ribeiro en 2016 [3]. En raison des limites de LIME, qui ne peut produire que des interprétations locales, nous avons décidé de nous plonger d'abord dans la valeur de Shapley et de la mettre en œuvre dans notre processus d'investissement.
Voici une agrégation de nos explications Shapley hebdomadaires ; elles nous montrent quelle catégorie de variables contribue au décile maximum de nos prédictions pour deux semaines différentes.
Au niveau individuel, avec l'aide de la valeur de Shapley, elle peut également nous aider à comprendre la décision des modèles sur chaque action, ce qui signifie que nous pouvons comprendre pourquoi les machines nous suggèrent d'acheter ou de vendre certaines actions. Nous passerons en revue deux exemples dans les pages suivantes.
Un exemple concret avec l'invasion de l'Ukraine
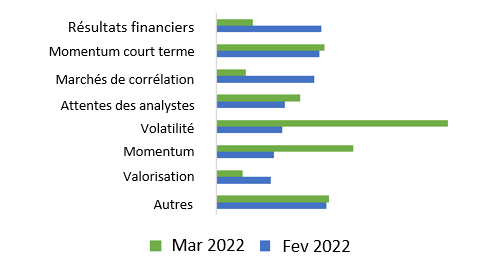 L'adaptation à de nouvelles conditions de marché est primordiale pour tout gestionnaire de portefeuille. Voici un exemple de la façon dont notre processus d'investissement s'est adapté au début de l'invasion de l'Ukraine par la Russie.
L'adaptation à de nouvelles conditions de marché est primordiale pour tout gestionnaire de portefeuille. Voici un exemple de la façon dont notre processus d'investissement s'est adapté au début de l'invasion de l'Ukraine par la Russie.
Par rapport à la mi-février 2022, la principale contribution à un rendement excédentaire positif élevé (alpha) est passée des résultats financiers à la volatilité en mars. Nous pouvons lire qu'en moyenne, au cours de la semaine du 2022-02-18, les facteurs d'investissement liés aux résultats financiers ont contribué à environ 1,30 % de la prédiction de l'alpha, mais qu'ils sont tombés à 0,40 % au cours de la semaine du 2022-03-11 pour les actions dont l'alpha est le plus élevé.
En résumé, nous nous éloignons de la majorité des événements de résultats financiers et nous sommes choqués par le début d'un événement mondial qui exerce une pression croissante sur certains segments des marchés financiers, faisant ainsi passer l'explication globale d'une catégorie à l'autre.
Ce graphique peut nous donner une idée générale de la décision hebdomadaire, globale ou par univers, et peut nous aider à vérifier si elle est alignée sur les nouvelles et les tendances du marché.
Une comparaison des facteurs de rendement excédentaire spécifiques aux actions
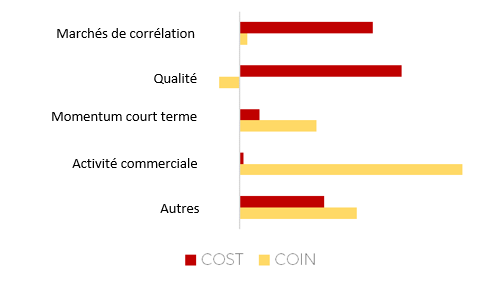
En fin juillet 2022, notre processus d'investissement a prédit deux rendements excédentaires très similaires pour la semaine suivante, mais pour deux raisons très différentes. Sans notre module d’IA explicable, nous vous aurions dit que Coinbase et Costco avaient la même prédiction de rendements excédentaires de +1,15 % pour la semaine suivante. Cette réponse manque de détails et il est difficile de s'y référer.
Même pour nous, nous avons besoin de plus pour comprendre la décision et utiliser l'outil de décomposition pour améliorer et maintenir l'intégration de nouvelles notions dans le processus d'investissement. Le module nous permet de comprendre en profondeur pourquoi la décision a été prise et ce qui a contribué à cette décision.
En décomposant le +1,15% pour Coinbase et Costco, nous pouvons comprendre pourquoi la décision a été prise. La décision relative à Coinbase était principalement due à une activité de trading anormale et à un momentum à court terme. La semaine suivant la prédiction, Coinbase a annoncé un partenariat avec Blackrock qui a fait grimper les actions de manière significative.
D'autre part, Costco a été acheté pour ses ratios de qualité et une certaine corrélation favorable avec les conditions du marché à l'époque.
Nous utilisons cet outil pour expliquer ce qui se passe dans le portefeuille et pour avoir une boucle de rétroaction à l'intérieur du processus de R&D.
Par ailleurs, la différence significative entre les moteurs pour une prédiction similaire est un avantage de diversification lorsqu'il s'agit de construire un portefeuille, et c'est une raison pour laquelle notre processus n'est pas reproductible par une exposition smart-beta.
COIN vs. COST - IA explicable - juillet 2022
Une illustration technique du processus
La valeur de Shapley est la contribution marginale moyenne attendue d'un joueur après avoir considéré toutes les combinaisons possibles.
En adoptant une approche simplifiée à l'aide des facteurs de Fama-French, nous pouvons illustrer comment nous calculons la valeur de Shapley pour le facteur d'évaluation avec une action spécifique. Dans le cas suivant, nous utilisons Apple inc. (AAPL).
La dernière étape de notre processus de modélisation nous donne une prédiction de l'alpha (rendements excédentaires par rapport à un indice de référence), sur laquelle nous voulons plus d'explications.
Tout d'abord, décomposons ce à quoi cela ressemble :
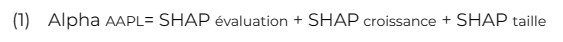
Par la suite, nous pouvons redimensionner l'équation en ayant une décomposition des poids pour chaque valeur SHAP :

Où les poids ont la relation suivante :
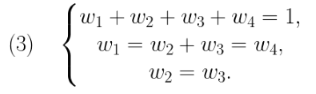
Nous pouvons répéter les étapes décrites par l'équation (2) et trouver les valeurs derrière la contribution marginale qui peuvent nous donner un aperçu de la façon dont notre modèle décompose l'alpha attendu.
Nous pouvons utiliser un package Julia appelé ShapML qui met en œuvre les travaux décrits par Štrumbelj, E., Kononenko, I [4].
En résumé, les méthodes XAI nous permettent de mieux comprendre nos modèles, et nous permettent d'améliorer nos travaux futurs sur la sélection de variables, et autres travaux d'ingénierie.
Nous continuons à explorer progressivement d'autres méthodes qui peuvent être adaptées pour interpréter nos modèles. En attendant, nous faisons progresser notre processus d'investissement par d'autres voies.
Référence
Lloyd S. Shapley. A value for n-person games, page 31–40. Cambridge University Press, 1988. doi: 10.1017/CBO9780511528446.003.
Scott M Lundberg and Su-In Lee. A unified approach to interpreting model predictions. In Advances in Neural Information Processing Systems, pages 4765–4774. NeurIPS, 2017
Ribeiro, Marco Tulio, Sameer Singh, and Carlos Guestrin. "Model-agnostic interpretability of machine learning." arXiv preprint arXiv:1606.05386 (2016).
Štrumbelj, E., Kononenko, I. Explaining prediction models and individual predictions with feature contributions. Knowl Inf Syst 41, 647–665 (2014).